Data Architecture
Pre-Class Readings and Videos
Please begin by watching the video below:
What do we really mean by data?
Data are pieces of information about individuals or observations organized into variables. By an individual or observation, we mean a particular person or object. By a variable, we mean a particular characteristic of the individual or observation.
A dataset is a collection of information, usually presented in tabular form. Each column represents a particular variable. Each row corresponds to a given individual (or observation) within the dataset.
Relying on datasets, statistics pulls all of the behavioral, physical and social sciences together. It’s arguably the one language that we all have in common. While you may think that data is very, very different from discipline to discipline, it is not. What you measure is different, and your research question is obviously dramatically different; whom you observe and whom you collect data from – or what you collect data from – can be very different, but once you have the data, approaches to analyzing it statistically are quite similar regardless of individual discipline.
Example: Medical Recordings
The following dataset shows medical records from a particular survey:
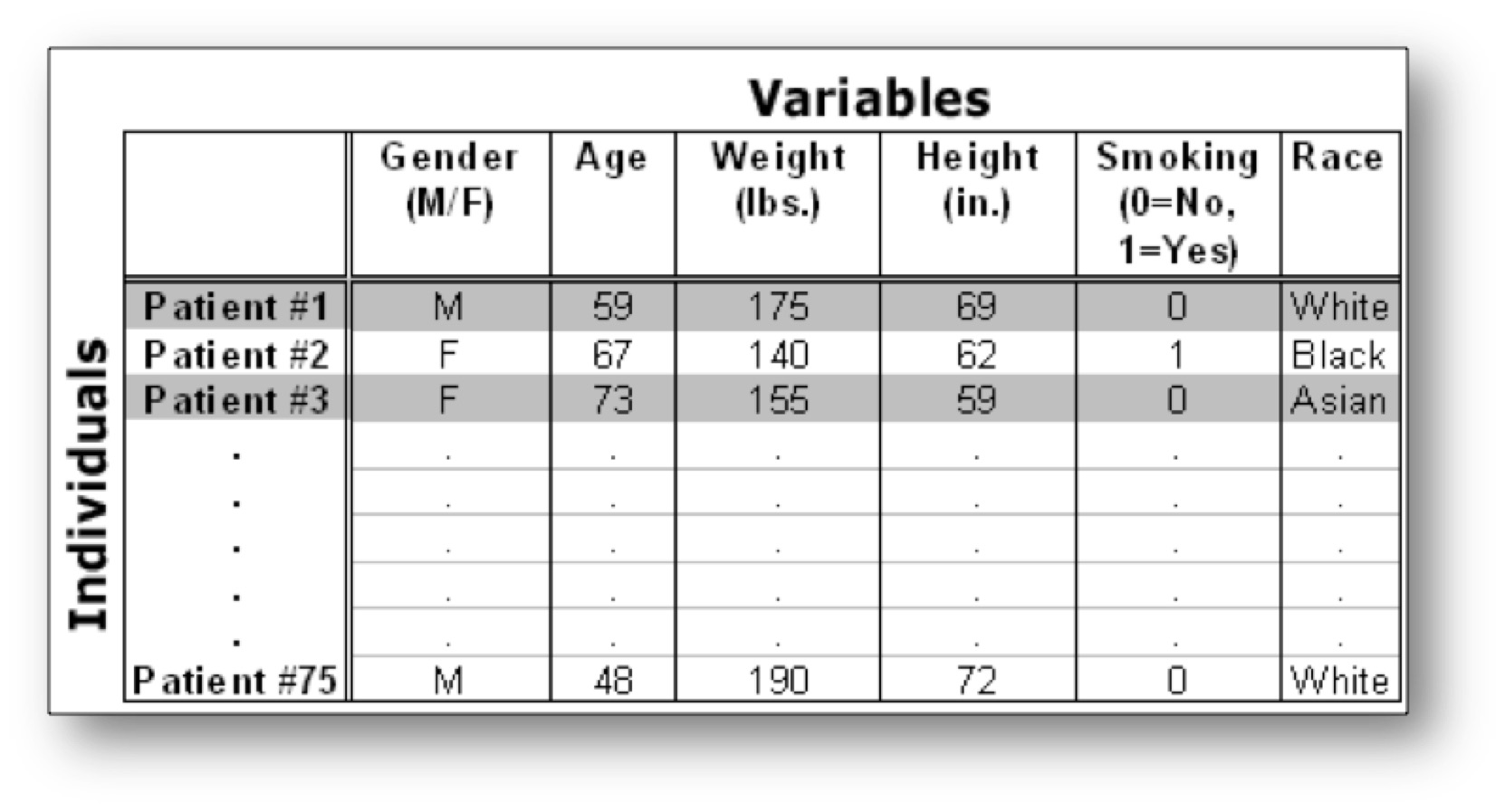
In this example, the individuals are patients, and the variables are Gender, Age, Weight, Height, Smoking, and Race. Each row, then, gives us all the information about a particular individual or observation (in this case, patient), and each column gives us the information about a particular characteristic of all the patients.
Variables can be classified into one of two types: quantitative or categorical.
- Quantitative Variables take numerical values and represent some kind of measurement
- Categorical Variables take category or label values and place an individual into one of several groups. In our example of medical records, there are several variables of each type:
- Age, Weight, and Height are quantitative variables
- Race, Gender, and Smoking are categorical variables
Notice that the values of the categorical variable, Smoking, have been coded as the numbers 0 or 1. It is quite common to code the values of a categorical variable as numbers, but you should remember that these are just codes (often called dummy codes). They have no arithmetic meaning (i.e., it does not make sense to add, subtract, multiply, divide, or compare the magnitude of such values.) A unique identifier is a variable that is meant to distinctively define each of the individuals or observations in your data set. Examples might include serial numbers (for data on a particular product), social security numbers (for data on individual persons), or random numbers (generated for any type of observations). Every data set should have a variable that uniquely identifies the observations. In this example, the patient number (1 through 75) is a unique identifier.
Pre-Class Quiz
After reviewing the material above, take Quiz 1 in moodle. Please note that you have 2 attempts for this quiz and the higher grade prevails.
During Class Tasks
During class you will be working on the following:
Mini-Assignment 1
Project Component A
Details of these tasks are located in the corresponding Coursework tab. Please see course schedule for submission deadlines. Please note that Project Components are due within blog entries for the course.